
- 2020/7/20 11:15:04
- 类型:转载
- 来源:
- 网站编辑:shixi01
很多人看到现在的CPU市场,都会感叹AMD在相同的价位,往往会提供更多核心数,线程数的产品,而Intel往往是频率稍高,但同样的核心数往往比AMD更贵,Intel为何在核心数上处于劣势?仅仅是因为Intel认为“多核无用”吗,还是因为技术原因延缓了Intel扩展多核性能的步伐?那什么样的技术问题让Intel在核心数大战中数量处于下风?这真的代表Intel竞争力不足了吗?
扩展多核有哪些益处?
多核CPU很显然,是一个完整封装的CPU产品中拥有多个理论上可独立工作的CPU内核的处理器,这里的多个内核可同时并行的执行一个任务中的多个线程,或者并发性的在不同的核心上执行不同的任务,每个内核理论上都有专属于自己的前端取指译码单元,缓冲区,执行单元,寄存器,缓存以及总线资源,现代多核CPU还拥有可共享的资源,比如最后一级缓存,内存总线等,都是能被一个CPU里的各个内核共享的,通过特定的总线保持数据的同步和交换以及一致性。
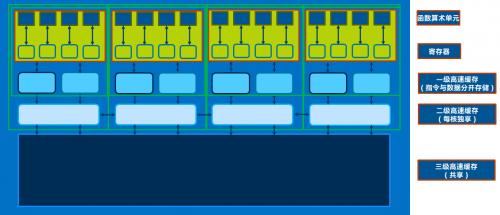
拥有更多核心的好处无疑是可以同时更快的执行某个可以并行或者并发的任务,我们往往想着一条路10个人修需要1个月,20个人就只需要半个月了,或者我们可以更好的同时执行多个不同的任务,比如我们可以把10个单线程满载的负载,合理分配到10个核心上执行,这样一定时间内,CPU就可以完成10个任务了。
并行和并发具体怎么区分?
并发实际上包含了并行,并行更像是并发中的特殊情况,并发可以理解为顺序的反义词,也就是像乱序一般的执行方式,比如要做饭,一边烧水,等水开的时间你可以去切菜,然后淘米,如果有几个人,那就多个人在执行这些事情,他们就像是在并发执行那样,而不是顺序的,等着水烧开了才去切菜,然后再去淘米煮饭 并行就像是一个特殊情况,虽然也是同时执行多个任务(线程),但是会强调执行的同时而非顺序的问题,比如切菜的时候同时几个地方在切,比如计算1+2+3+...+100,会同时分成几个部分同时计算比如1加到20和21加到40,41加到60...这样的任务可以同时进行,这也更像是循环展开的并行优化方法。
单核处理器就无法执行并发和并行任务了吗?很多人认为单核处理器就一定只能执行单个任务,与并行和并发毫无关系,实际上现代处理器可以实现ILP和DLP,ILP便是指令级并行,通过分析指令流,只要彼此互相不依赖,就可以同时发射多个指令到执行单元并顺利执行然后retire,就实现了多个指令被同时执行的目的,实现了多个指令的并行,循环展开就是一种典型的指令级并行优化方法,ILP的数据并行中也存在DLP,比较典型的实现是SIMD,也被称为向量并行,单个指令打包多个数据的计算,如SSE,AVX,这样同时也实现了多个数据的处理。
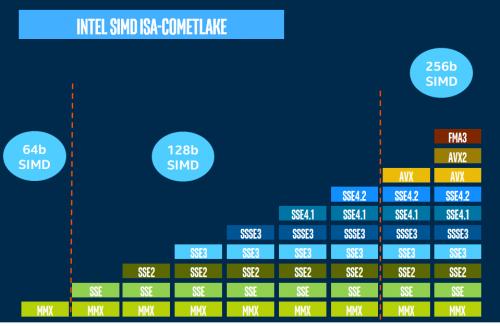
单核单线程处理器只能同时执行一个线程内的多个指令并行和数据并行,那么能不能实现多个线程的并发?显然可以,单核cpu存在多线程,但传统单核单线程处理器并不在同一时刻运行这些线程 每个线程就绪后都会等待调度器分配cpu给线程 可能过一会又把cpu分配给另一个线程,实际单一时刻永远只会单线程在跑,这就是单核处理器的并发执行多线程的概念,而之后,处理器加入的同步多线程技术使得一个CPU内核一旦某个线程出现阻塞,便可立即在单个时钟周期的开销下调度到另一个线程,并利用其固有的指令队列,缓冲区资源来利用闲置执行资源进行并发执行,由于这个切换速度很快,看上去就像是"同时"在处理多个线程一样实现了类似线程并行的效果,也可以这么说,单核处理器存在多线程的并发,但严格来说不能实现多线程的并行,只能实现一个线程内的指令级和数据级并行。
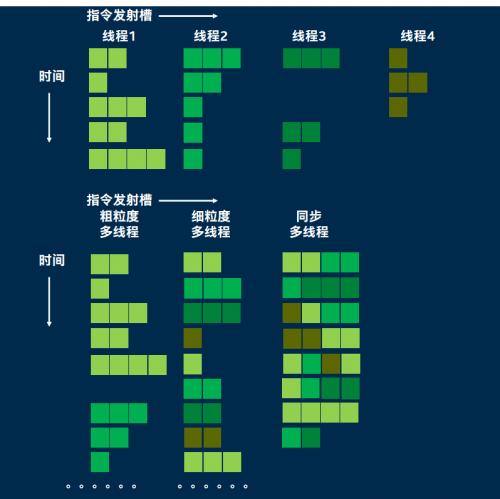
同步多线程的快速切换能力让程序看上去是多个线程同时执行的,能大幅提高总体执行单元利用率
我们日常生活并行与并发的需求很高吗?
很多人的理解是,如果我一边上网,然后聊天,后台开着音乐播放器,网页或者本地的电影,这样就是高并发使用场景了,就非常迫切的需要多核多线程,实际上CPU每秒可以执行数十亿个指令周期,一个5GHz的处理器拥有50亿个时钟周期,而前面说到,即使是单个核心,也可以同时执行多个指令和多个数据的处理,实现多线程的并发,这么一来CPU每秒可以执行的指令和数据量相当庞大,你的日常上网,聊天,看电影可能加起来也就能占用1个核的资源,CPU即使在一个内核资源的情况下,就可以保证多个前台轻量日常使用加上很多后台挂起的程序的系统无缝运行了

系统运行时有数百个进程和上千个线程存在,但不代表你需要一百核处理器
那我们什么情况下才能充分运用向量并行和多线程并发性能?
往往服务器的场景使用才能并发多个高负载需求,从而利用多核处理器的多线程高并发性能,日常生活中我们的使用更多的是单个大型任务,通过并行优化从而使得程序变得高度并行,从而让我们从多核处理器中受益,同时这样的任务也会充分利用指令级并行和数据级并行的特点,将多核,宽矢量,多发射的现代处理器性能充分发挥出来,如基于光线追踪的渲染,每条光线的处理可以并行的处理,如大学中进行矩阵计算为基础的科学运算和AI计算的科研工作,矩阵的乘法加法计算可以并列,分块的进行,比如影音图像处理,视频爱好者和主播的视频的编码工作,不同图像每帧之间,同一帧的不同位置的编码也可以并行的进行。
那回到最初的问题,既然多核性能能加大处理器的峰值性能,为什么Intel的核心数没有那么多呢?
实际上,用户要想获得最佳的性能体验,不仅需要一个强大的峰值性能,也需要尽可能少的短板,扩展一倍的核心数,固然相当于比过去处理器多出了一倍的执行单元,但提高并行性能如上所述,可以通过宽流水线,多发射,宽矢量指令SIMD来实现,同时通过加深乱序执行性能,分支预测性能和同步多线程SMT性能,在把单个核心的并行和并发潜力发掘后,再去扩宽多核心的实现,所以,从酷睿i系列开始,虽然Intel处理器一直保持四核心八线程,但实际上SIMD矢量位宽从128位到256位再到256位乘加融合,以及最新Icelake的512位乘加融合执行性能,同时乱序执行窗口从128个队列扩大到Skylake的224个队列,Icelake还拥有超过300个队列的乱序窗口和重排缓冲区,AGU端口也不断增加,可以说,Intel在尽可能挖掘单核心下的并行并发能力后,才去堆核,因为多核的运用协调一致运行的难度更高,能在一个核内完成显然更为有利于用户和开发者的使用,所以Intel在不断优化设计更宽的流水线,更强大的执行单元,更深的缓冲区,而在10nm受阻,微架构的优化进度放缓后,Intel便开始了增加核心数的手段,从8代的6核,到9代的8核,10代的10核,逐渐提高了核心数量,但架构的变化则基本没有,只有Icelake产品是全新的架构,但依旧为4核心8线程。但无论如何,即使是高度并行的程序,也需要多线程+矢量化双管齐下,才是最佳的并行性能
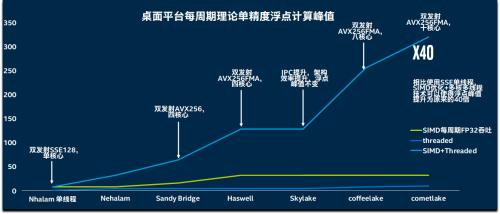
多核扩展有哪些挑战:
很多人可能认为,只要有了对应的总线,放入了对应的核心,多核就能理所应当的运行起来,有人会说Intel怎么核心堆的这么慢,其实当代处理器越来越受到ILP wall,memory bound和power wall的限制,性能提升开始实质性变慢,即一味扩大指令级并行度,处理器的乱序窗口和前端译码无法保证填满如此多的执行单元,同时功耗密度的提高限制了频率的增长,而Memory Bound则反映了内存速度与CPU速度的差距,而且会逐渐限制CPU同时处理更多的数据,往往密集计算,CPU的性能被内存带宽所限制,而日常快速响应的请求,受制于内存的延迟,但也正是因为任务量的变化,处理器开始越来越重视多核的设计,多核时代已经来临,只不过要想真正做好,需要克服相当多的系统障碍,才能做到最佳的效果。
所以要想真正做到最好的多核体验,硬件方面需要一个强劲的单核性能作为基础,同时控制内存系统(包括DRAM和Cache)的延迟,同时要随着核心数量和数据处理量的提高,尽可能提高内存的带宽,又要保证此时的延迟不能过高,同时多个核心,尤其是远端的核心通信的延迟更低,经过的中转越少越好,同时软件也需要与时俱进,用户要有足够大的数据处理需求,同时诞生更多高性能的常用软件,而对多核的调用,需要多个层面的软件开发者和硬件工程师配合才能充分达成,离不开各种高性能库的应用,这些库都是精通硬件与软件的工程师贡献的,在这种情况下,多核性能才变得真实有效,有利于用户的实际体验。而这些周边配套的发展不是一蹴而就的,需要互相促进,互相发展,同时一些任务注定难以被“并行”,正如一个例子,我们不可能同时将一栋楼的第二层和第三层同时由两组人进行修建,而只能同时修建第二层,然后才是第三层,而第二层修好,到开始修第三层这部分,就很难并行的施工,这意味着不受并行优化影响的核心频率值也永恒的重要,而全方位发展的一个代价就是,付出的成本会更高,也就很难过于激进的推进某一个参数,比如单纯提高核心数而不顾内存带宽和因此带来的延迟增长。
并行的难题也被一个叫 “阿姆达定律”概括,即一个系统中,不可避免有一些资源必须串行访问,这限制了我们的加速比,这其中的原因与我们没有能够并行化处理而只能串行执行的代码以及存储器资源,通信效率密切相关,或许有的人会拿一些程序说,已经有程序能充分利用超多CPU核心,但这类高性能应用对应的场景非常少见,真实使用场景中,要想让用户获得最佳的体验,就只能在通信延迟,内存性能,核心频率等多方面下功夫,这注定核心数的增加就不能过于激进,同时因为单个核心的矢量处理能力提高,更多核心+更宽SIMD面临一个问题,那就是是否有如此之多的数据需要或者能够被并行
通过Matlab运行一个存在并行资源争夺的计算项目来进行验证,在测试中通过并行多个2048*2048元素量的向量乘法,FFT和矩阵乘实例进行测试,在配置四通道128GB 3600Mhz内存的i9-10980XE设备上,当扩展到一定程度的核心数后,体现出了阿姆达定律的特征,即使我们继续增加了并发核心数(下图横轴),但之后取得的效果越发不理想(纵轴为相对单核的加速比,并非实际成绩),收益逐渐变差,难以获得线性扩展能力,
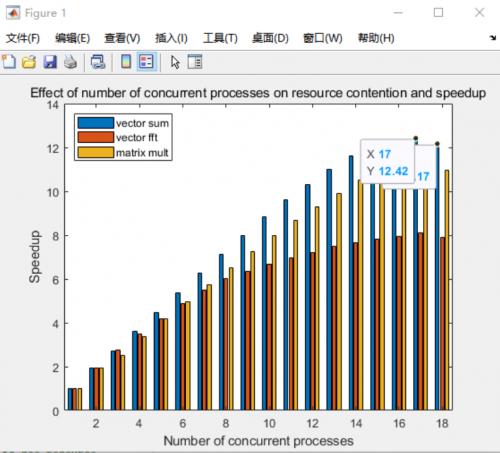
而高密度的计算对于桌面主流平台,也就是普遍只有双通道的计算机系统来说,更是一个巨大的挑战
测试环节
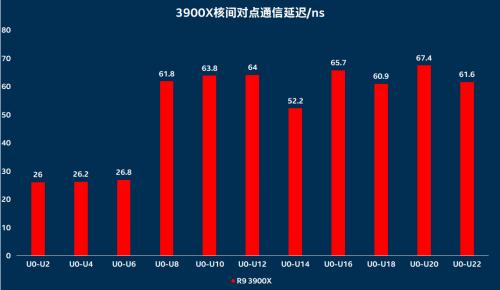
在测试环节,我们通过AMD与Intel的产品的一些对比来看一下,我们需要了解的是,对于超多核心处理器,我们并不能简单认为核多就一定好,而是根据自己实际负载的特点来选择产品,无论是Intel,还是AMD产品,都不可能在什么负载下,核心增长就一定带来对应的增长,参与对比的3900X与10900K使用一样的内存,以便应对共同的内存问题,10900K 10核高频,但也只支持双通道内存,不可避免的遇到内存资源瓶颈问题,同时我们可以发现,AMD为了应对内存瓶颈,缓存规格相当高,3900X拥有与3950X一样的三级缓存,拥有AMD 2个CPU Die,4个CCX下的全部64MB L3。

虽然Intel在努力保证处理器均衡发展,瓶颈固然很多时候无法避免,但在苛刻的复杂性能需求下,Intel产品的短板要小很多
最明显的一个特点,AMD处理器固然核心数量较多,在双通道桌面平台甚至提供12和16核产品,但实际其每四个核心为一个CCX,2个CCX为一个CPU die,CCX内四个核心通信速度很快,但只要需求与其他CCX的核心通信,就需要通过CPU上的I/O Die进行中转路由,延迟便会大幅度提高。
而Intel 10900K 10个核心的直接通信延迟则始终保持在一个稳定较低的范围(40ns),
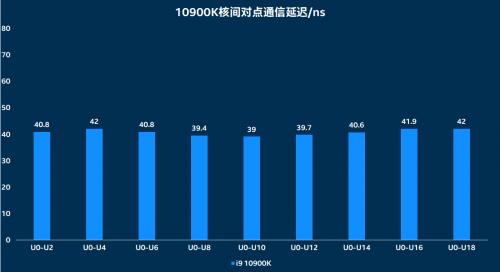
(以上数据,数值越低越好)


报纸客服电话:4006677866 报纸客服信箱:pcw-advice@vip.sin*.c*m 友情链接与合作:987349267(QQ) 广告与活动:675009(QQ) 网站联系信箱:cpcw@cpcwi.com
Copyright © 2006-2011 电脑报官方网站 版权所有 渝ICP备10009040号