
- 2025/3/14 12:19:17
- 类型:转载
- 来源:
- 网站编辑:阿卡
过去两个月来国产大模型在性能、算法上的持续创新,让AI开始真正走入普通人的生活中。但与此同时,AI的迅速普及也引发了人们对于AI侵犯隐私、虚假信息泛滥等“副作用”的担忧。
今年两会上,不断有代表呼吁加强对AI乱象的治理。过去一年来因为小米汽车而备受追捧的网红企业家雷军建议,应加快AI换脸拟声技术的立法进程,明确技术应用的边界。他说,他自己就是AI换脸拟声的重度受害者,互联网上有大量雷军AI配音的恶搞视频。明星靳东也对外呼吁,有很多喜爱他影视剧的观众因为AI换脸而受骗,呼吁建立更好的规则应对。
如果说AI换脸目前主要针对的还是名人,AI幻觉则已经影响到普通人的生活。两会期间,大模型的AI幻觉成为代表们讨论的高频词汇。
科大讯飞董事长刘庆峰说,生成式人工智能存在幻觉,特别是深度推理模型的逻辑自洽性提升,使得AI生成内容真假难辨。同时,带有算法偏差的虚假信息会被新一代AI系统循环学习,形成“数据污染-算法吸收-再污染”的恶性循环。他呼吁行业关注AI幻觉信息充斥互联网造成的危害。
360集团创始人周鸿祎也在两会期间对媒体表示,AI幻觉虽然有利于文学创作,但在AI安全方面,幻觉可能会带来严重问题,比如在医疗、法律、金融等专业领域,大模型一旦胡乱编造,就会带来严重后果。
事实上,在DeepSeek爆火之后,中文互联网上利用AI生成的虚假信息已成泛滥之势。早在农历新年期间,中文互联网上就流传一篇英伟达创始人黄仁勋对DeepSeek看法的文章,甚至还有一篇以DeepSeek创始人梁文锋口吻回应游戏科学冯骥的公开信。
这两篇文章都言辞恳切,细节满满,令人动容,文章一时之间风靡全网,大量网友争相转发评论。但很快,相关文章都被辟谣,均是出自 AI 手笔。
过去一个月来,诸如此类的AI虚假信息有增无减。前两天,一篇名为《DeepSeek的胡编乱造,正在淹没中文互联网》刷屏。作者在文章中指出,类似于DeepSeek这样的深度推理模型,训练过程中特别注重奖惩极致,AI会迎合用户的意识来生成内容,不少自媒体已经开始借助AI来批量化生成真假难辨的信息,并海量投放到互联网上。
AI平台Vectara发布的大模型幻觉榜单中也指出,相较于DeepSeek-V3的 3.9%幻觉率,推理模型DeepSeek-R1的幻觉率高达14.3%。
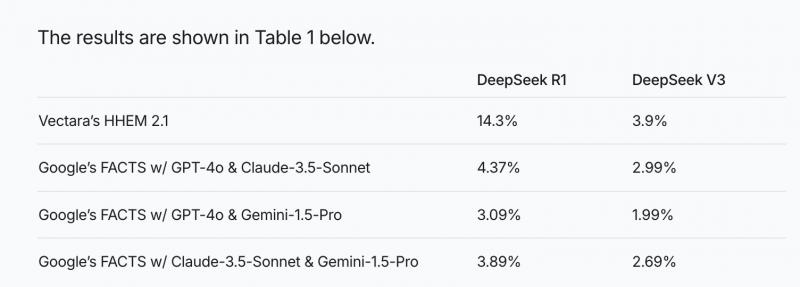
Vectara数据
但普通民众很难厘清其中的差异。过去一段时间以来,患者拿着DeepSeek的诊疗结果去医院开药的新闻屡见报端,媒体评论称AI正在成为医患关系的新挑战。部分地区的监管机构不得不紧急发文强调,严禁医院及药店等医疗场所接收人工智能等自动生成处方。
刘庆峰在两会期间接受媒体采访时指出,普通民众对AI技术原理及生成机制的认知理解不足,极易将算法输出的“幻觉数据”误判为真实可信信息。当大模型生成的“幻觉数据”充斥互联网信息生态时,不仅会削弱公众信任,还可能影响社会稳定。
不久前,就有一条称“中国80后累计死亡率为5.2%”的谣言在互联网上广为流传,但如果不是对人口问题关注的专家学者,可能很难分辨出其中的猫腻。不少普通民众在互联网上转发相关信息,引发恐慌情绪。
中国人民大学教授李婷公开辟谣,这则数据错误非常明显,因为专业统计数据中死亡率会用千分率表示,而非百分率。她猜测,虚假的死亡数据很可能是AI生成的,并在对AI大模型的提问中证明了这一观点。
作为坚持全栈自主可控的国产大模型代表人物,刘庆峰建议从技术研发和管理机制上双管齐下,来防范AI幻觉信息的泛滥。他在建议中提出,一是构建安全可信数据标签体系,提升内容可靠性;二是研发AIGC幻觉治理技术和平台,定期清理幻觉数据。
“我们必须尽早建立人工智能生成内容的溯源机制,这一机制应像‘拉网’一样持续清理错误信息,并为科研机构和个人提供相应工具,帮助他们自主筛查、判断信息的真实性。”刘庆峰说。
大模型引爆市场两年来,全球已有不少针对于人工智能的监管条例出台,比如欧盟的《人工智能法案》、美国的《算法问责法案》等等,我国也相继出台《生成式人工智能服务管理暂行办法》(下文简称《办法》)等相关监管条例,针对人工智能传播虚假信息、侵害个人信息权益、数据安全和偏见歧视等问题划定监管红线。
当然,AI存在幻觉并不意味着我们就要拒绝AI。人工智能是大势所趋,AI自主生成内容正是大语言模型的突出特点,也是最具想象力的技术突破。我们既要坚决反对AI幻觉数据在互联网上的泛滥,但同时也要审慎地看待大模型的“AI幻觉”。
过去两年来,行业中也有不少针对AI幻觉问题的有益探索和尝试。比如今年1月讯飞星火推出的基于智能体的全新长文本框架,在行业首发了句子级溯源功能,可以利用大规模网页和书籍数据进行知识关联式合成,使得知识回复的错误率降低了 40%。
在国产大模型逐渐在千行百业落地应用过程中,诸如医疗、能源、教育等对模型准确率要求更高的行业龙头企业也与AI厂商们共同探索,不断消除AI幻觉的影响。
此前,国家能源集团与科大讯飞合作的智能无人评审系统,通过大量行业知识的学习与AI技术创新,使得系统的智能评审准确率达 97%,实现对非招标采购全类别、全评审方式全覆盖,在国资委网站上被作为典型案例推荐。
尤其是在持续深入落地行业过程中,大量来自行业内部的真实语料质量数据被积淀下来,可以持续反哺行业专业大模型的训练与开发,降低模型的幻觉程度,不断提升模型在专业领域的智能水平。此前,讯飞就凭借在医疗、教育等行业的多年深耕,积累了亿级的高质量高质量医学数据以及海量教育数据集。
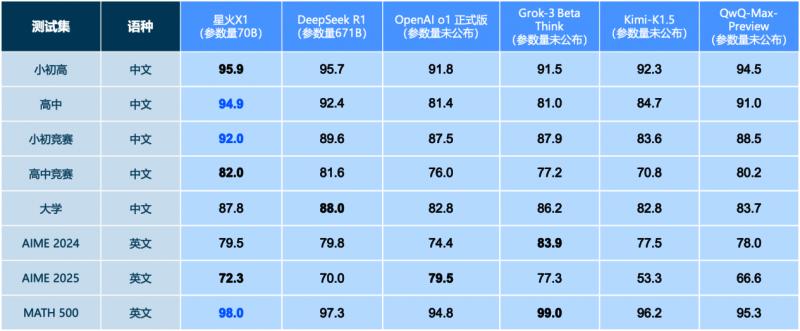
依托这些多行业、多领域的高质量数据集,讯飞星火的AI幻觉程度大幅降低。最新升级的推理模型星火X1仅用70B参数规模,就实现了数学能力对标671B参数规模的DeepSeek-R1。
AIGC已经是不可阻挡的未来,我们即将迎来一个与AI共存的时代。但在大模型尚处于早期技术发展阶段的当下,AI幻觉仍然是一个无法彻底根治的问题。这既是以概率为基础的大语言模型的固有特性,同样也是我们必须克服的挑战。
Copyright © 2006-2021 电脑报官方网站 版权所有 渝ICP备10009040号-12